New FDA Requirements for Cybersecurity
The FDA has released new cybersecurity regulations for medical device suppliers
The Food and Drug Administration (FDA) has announced that medical devices must now meet specific cybersecurity guidelines. Cyber-attacks against healthcare organizations increased by 74% last year, and attacks on the software supply chain have increased an average of 610% per year since 2020.
The federal government has been worried about the lack of cybersecurity maturity in the healthcare industry, especially with so many medical devices being connected to the internet. The fear is these insecure devices would lead to increased attacks and this set of regulations is part of a coordinated strategy to address these increased risks.
These new security requirements were introduced as part of a $1.7 trillion federal omnibus spending bill signed by President Joe Biden in December. The FDA must update its medical device cybersecurity guidance every two years.
What’s in the new requirements?
Device manufacturers must now submit plans to monitor, identify, and address post-market cybersecurity vulnerabilities and exploits, including coordinated vulnerability disclosures and plans, within a reasonable timeframe. Suppliers must also make security updates and patches available on a regular schedule and in critical situations
The requirement for vulnerability disclosure is in line with what we are seeing from NIST, CIS and other standards organizations. Unfortunately, many medical device suppliers do NOT currently have vulnerability disclosure programs.
Software engineers must design and maintain procedures to demonstrate, with reasonable assurance, that the device and related systems are secure. This is commonly referred to as “secure by design” and includes embedding security scanners and other technologies into the day-to-day engineering processes. Engineering teams must also create updates and patches for the device and connected systems that address known vulnerabilities on a reasonably justified regular cycle.
If issues are discovered outside the software development process, the manufacturer must publicly disclose critical vulnerabilities that could cause uncontrolled risks as soon as possible.

If you want to learn more about DevSecOps and how it can help your teams embed security into the software development processes you can check out our blog post.

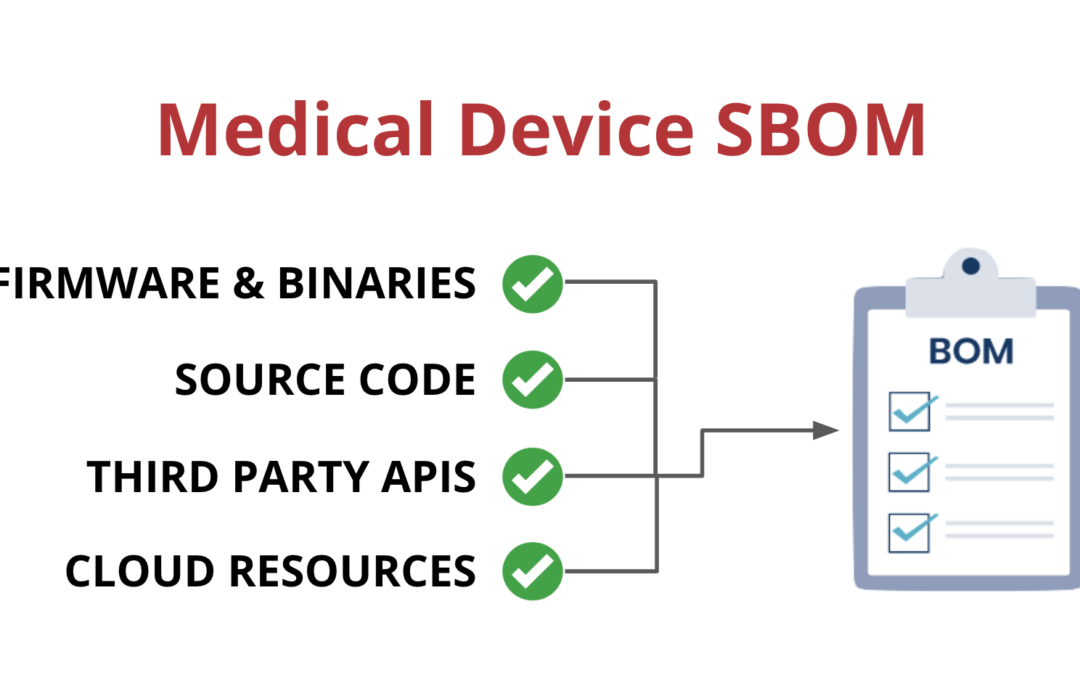
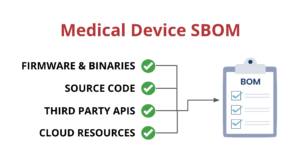
Medical device suppliers must also include a software bill of materials (SBOM) containing all commercial, open-source, and off-the-shelf software components while complying with other FDA requirements “to demonstrate reasonable assurance that the device and related systems are cyber secure.”
SBOMs need to be up-to-date, accurate and validated by a third party. If you want to learn more about medical device SBOMs, you can check out our blog post on the subject.
So, how do can you address these new requirements?
Medical device suppliers who are building custom software and/or firmware will need to implement several technologies to address the new FDA requirements. Let’s go through each of these one at a time:
- Asset discovery & management – The first place to start is with a asset discovery and management solution that will give you insight into what you have and is it internet connected.
- Application security analysis – Once you know what your assets are you need to make sure that the software you are building is secure. Software composition (SCA) tools are a great place to start as they help you understand what open-source libraries are in your applications.
- Vulnerability management – Next up is implementing a vulnerability management platform that will find all vulnerabilities in your hardware and software and prioritize them for you. This helps you prioritize what to focus on and what’s not really a problem.
- SBOM – The final part to addressing the FDA’s requirements is implementing an automated third-party SBOM program. This can be added to your software development automation so that everytime a new release is built for your medical device its been tested and a SBOM has been created.

Complete security coverage across the whole SDLC
The SecureStack platform offers an integrated suite of security tools that work together and all report to the same dashboard. One unified view and one subscription to pay. Easy.

Paul McCarty
Founder of SecureStack
DevSecOps evangelist, entrepreneur, father of 3 and snowboarder
Forbes Top 20 Cyber Startups to Watch in 2021!
Mentioned in KuppingerCole's Leadership Compass for Software Supply Chain Security!